Diese Oberfläche ist dafür gedacht, mit lokalen KI-Modellen zu chatten. Das ausgewählte Modell läuft nicht irgendwo im Internet, sondern auf dem eigenen Rechner oder im eigenen Netzwerk. In der Oberfläche kann man pro Chat verschiedene Einstellungen anpassen. Das ist praktisch, weil nicht jedes Modell gleich arbeitet. Kleine Modelle brauchen oft knappere Vorgaben. Größere Modelle kommen meist besser mit längeren Antworten und mehr Kontext zurecht.
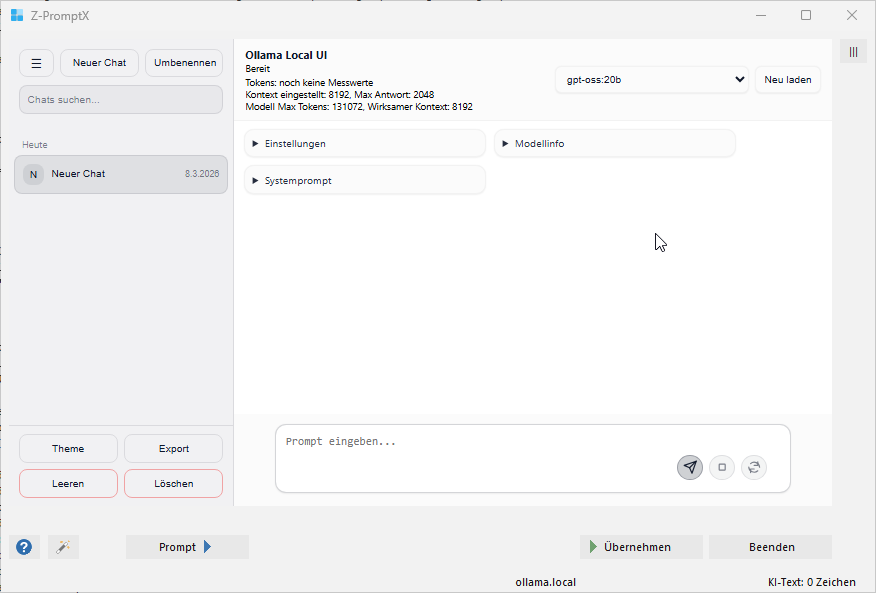
Die wichtigsten Einstellungen befinden sich im Bereich Einstellungen. Zusätzlich gibt es noch Modellinfo und Systemprompt. Alle Werte gelten pro Chat und werden automatisch gespeichert.
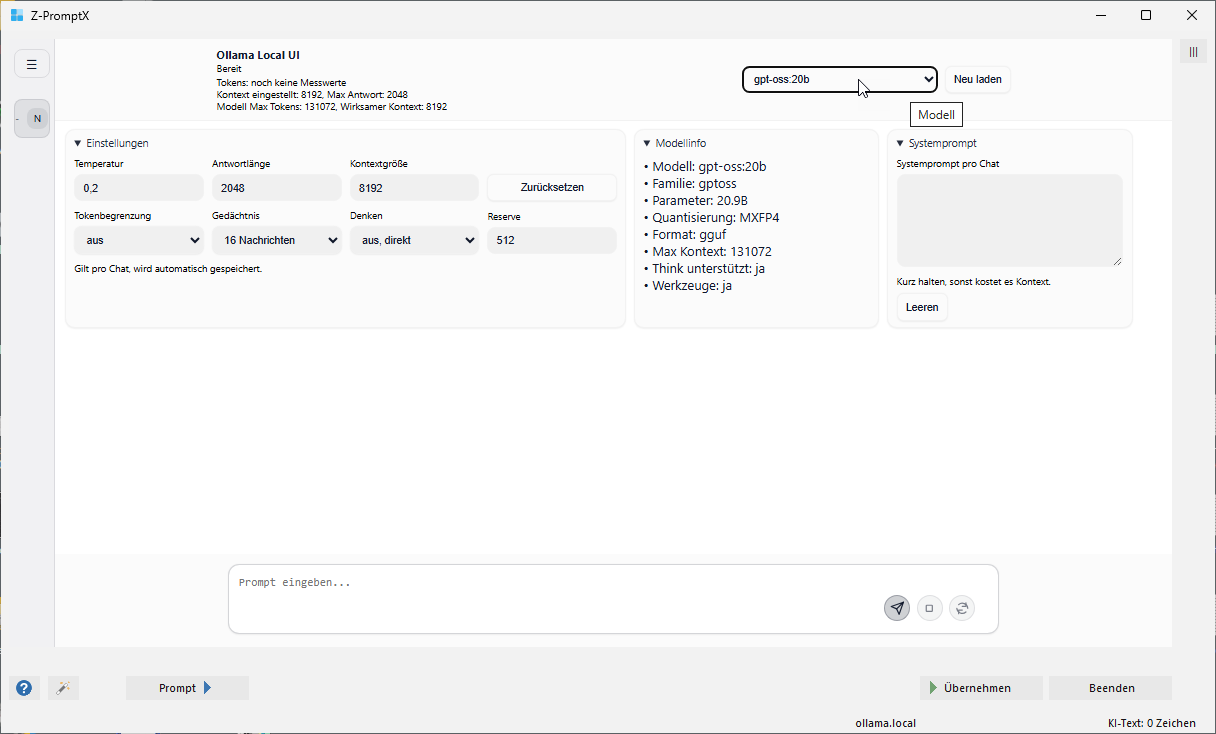
Modell auswählen
Oben rechts kann ein Modell ausgewählt werden. Mit „Neu laden“ wird die Modell-Liste erneut vom lokal installierten Ollama-Server geholt. Nach der Auswahl wird auch die Modellinfo geladen. Die Oberfläche versucht das Modell dabei kurz vorzubereiten, damit die erste echte Anfrage nicht ganz so träge startet.
Praktisch bedeutet das:
Wenn mehrere lokale Modelle installiert sind, kann man für jede Aufgabe das passendere Modell nehmen. Ein kleines Modell für kurze Alltagsfragen, ein größeres Modell für anspruchsvollere Texte.
Temperatur
Die Temperatur steuert, wie frei oder wie nüchtern das Modell antwortet. In der Datei ist als Standardwert 0,2 hinterlegt.
Für die Praxis gilt:
Niedrige Temperatur passt gut für sachliche Antworten, Zusammenfassungen, Umformulierungen, technische Fragen und alles, was eher ruhig und vorhersehbar sein soll. Höhere Temperatur passt eher für Ideen, kreative Formulierungen oder wenn das Modell freier schreiben soll.
Als einfache Faustregel:
Für Alltag und verlässliche Antworten ist ein niedriger Wert meist besser. Kleine lokale Modelle profitieren besonders davon, weil sie dann weniger abschweifen.
Antwortlänge
Die Einstellung „Antwortlänge“ steuert, wie lang die Antwort maximal werden darf. Technisch ist das die Ausgabegrenze des Modells. In der Datei wird dafür num_predict verwendet, der Standardwert ist 2048.
Praktischer Nutzen:
Ein kleiner Wert sorgt für kurze, schnelle Antworten. Das ist gut für Fragen wie „Erkläre kurz“, „Gib mir drei Punkte“ oder „Fasse das zusammen“.
Ein größerer Wert ist sinnvoll, wenn das Modell ausführlicher schreiben soll, etwa für Entwürfe, Anleitungen oder längere Erklärungen.
Wichtig:
Zu hohe Werte bringen nicht automatisch bessere Antworten. Gerade bei kleineren Modellen kommt oft mehr Text, aber nicht unbedingt mehr Qualität. Für den Alltag ist ein mittlerer Wert meist sinnvoll.
Kontextgröße
Die Kontextgröße bestimmt, wie viel vom bisherigen Gespräch und von Zusatztexten das Modell gleichzeitig berücksichtigen kann. Technisch ist das num_ctx, in der Datei ist 8192 als Standardwert vorgesehen.
Praktischer Nutzen:
Mehr Kontext ist nützlich, wenn das Modell sich an mehrere frühere Nachrichten erinnern soll oder wenn längere Texte verarbeitet werden. Weniger Kontext spart Speicher und kann bei kleinen Modellen oder schwächerer Hardware sinnvoll sein.
Einfach gesagt:
Wenn das Modell den Faden verliert, kann mehr Kontext helfen. Wenn der Rechner knapp wird oder Antworten zäh werden, kann ein kleinerer Wert besser sein.
Gedächtnis
Die Einstellung „Gedächtnis“ legt fest, wie viele der letzten Nachrichten an das Modell mitgeschickt werden. In der Oberfläche kann man zwischen 8, 16, 24, 32, 48 und 64 Nachrichten wählen. Standard ist 16.
Praktischer Nutzen:
Ein kleiner Wert ist gut für einfache, kurze Gespräche. Das spart Platz im Kontext. Ein größerer Wert ist nützlich, wenn das Gespräch länger läuft und frühere Aussagen wichtig bleiben sollen.
Für die Praxis:
Wenn das Modell alte Details vergisst, den Wert erhöhen. Wenn die Antworten langsamer werden oder das Modell sich verzettelt, den Wert eher kleiner halten.
Denken
In der Oberfläche gibt es eine Einstellung „Denken“ mit drei Möglichkeiten: „aus, direkt“, „anzeigen“ und „ausblenden“. Diese Einstellung ist vor allem für Modelle wichtig, die einen Denkmodus unterstützen. Die Datei nennt hier ausdrücklich Modelle wie gpt-oss, deepseek-r1, qwen3 und einige weitere.
Was das praktisch bedeutet:
aus, direkt ist für den Alltag oft die beste Wahl. Das Modell soll direkt antworten, ohne sichtbare Denkspur.
anzeigen ist nützlich, wenn man sehen will, wie das Modell intern arbeitet. Das kann beim Testen interessant sein, ist für normale Nutzung aber oft unnötig.
ausblenden ist sinnvoll, wenn das Modell intern denken darf, man die Denkspur aber nicht im Chat sehen möchte.
Besonders wichtig:
Für gpt-oss:20b gibt es in Z-PromptX eine Sonderbehandlung. Dort wird das Denken standardmäßig eher zurückhaltend behandelt, wenn man es nicht ausdrücklich anzeigen lässt. Empfehlung für Anwender:
Im normalen Gebrauch zuerst „aus, direkt“ probieren. Das wirkt meist ruhiger und klarer.
Tokenbegrenzung
Die Oberfläche kann den Verlauf zusätzlich über eine Tokenbegrenzung steuern. Diese Funktion ist standardmäßig aus. Wenn sie eingeschaltet wird, versucht die Oberfläche den Verlauf so zu kürzen, dass genug Platz für die Antwort bleibt. Dafür gibt es auch die Einstellung „Reserve“. Standard für die Reserve ist 512.
Praktischer Nutzen:
Das ist hilfreich bei kleineren lokalen Modellen oder bei längeren Chats. Sonst kann es passieren, dass zu viel alter Verlauf mitgeschickt wird und für die eigentliche Antwort nicht mehr genug Platz bleibt.
Die Reserve ist eine Sicherheitszone. Sie lässt dem Modell noch Luft für die Ausgabe.
Einfach gesagt:
Wenn lange Gespräche unzuverlässig werden, ist diese Funktion oft sinnvoll.
Systemprompt
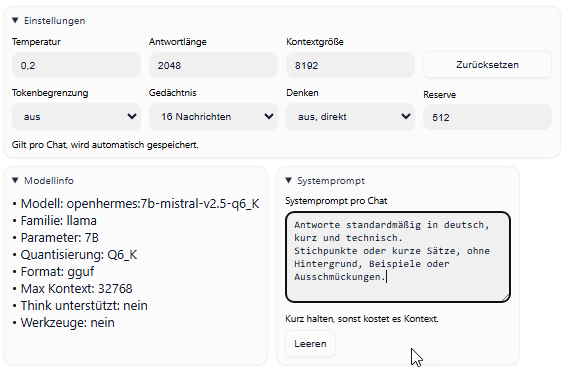
Im Bereich „Systemprompt“ kann pro Chat ein kurzer Grundbefehl hinterlegt werden. Praktischer Nutzen:
Damit kann man dem Modell eine feste Arbeitsrichtung geben, zum Beispiel:
„Antworte knapp und sachlich.“
oder
„Erkläre in einfacher Sprache.“
Das ist vor allem nützlich, wenn ein Modell immer in einem bestimmten Stil antworten soll.
Wichtig:
Ein zu langer Systemprompt nimmt Platz weg, der dann für den eigentlichen Chat fehlt.
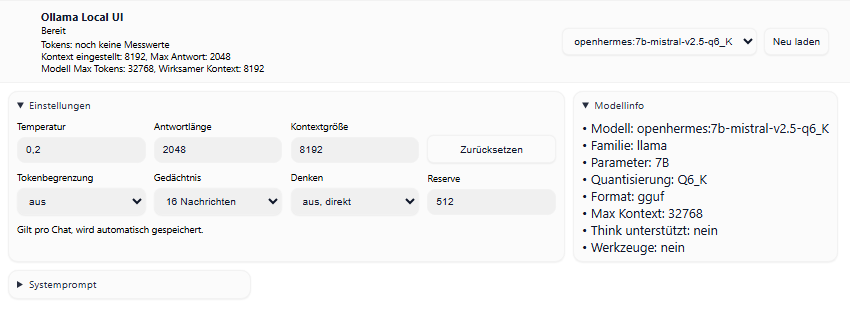
Modellinfo
Im Bereich Modellinfo zeigt die Oberfläche verschiedene technische Angaben zum ausgewählten Modell. Dazu gehören zum Beispiel Modellfamilie, Parametergröße, Quantisierung, Format, Kontext aus dem Modell, maximaler Kontext, Unterstützung für Denken und Werkzeugnutzung. Zusätzlich kann auch die letzte Geschwindigkeit angezeigt werden. Für Anwender ist daran vor allem interessant:
- Die Parametergröße gibt grob an, wie groß das Modell ist.
- Der Kontext zeigt, wie viel das Modell grundsätzlich verarbeiten kann.
- Think unterstützt zeigt, ob das Modell mit dem Denkmodus überhaupt etwas anfangen kann.
Das hilft, wenn man mehrere lokale Modelle vergleicht und sich fragt, warum eines anders reagiert als das andere.
Welche Einstellung für welchen Zweck
Für kleine lokale Modelle ist es meist sinnvoll, mit eher vorsichtigen Werten zu arbeiten. Also niedrige Temperatur, normale Antwortlänge, nicht zu viel Gedächtnis und Denken eher aus. Das macht die Antworten oft stabiler.
Für größere Modelle kann man mehr wagen. Also mehr Kontext, bei Bedarf mehr Gedächtnis und längere Antworten. Wenn das Modell Denken sauber unterstützt, kann man das testen, muss es aber nicht dauerhaft eingeschaltet lassen.
Einfache Startempfehlung für den Alltag
Wenn man nicht lange herumprobieren will, ist diese Richtung ein guter Start:
- Temperatur niedrig lassen.
- Antwortlänge mittel lassen.
- Kontextgröße auf dem Standardwert lassen.
- Gedächtnis auf 16 lassen.
- Denken zuerst auf „aus, direkt“ stellen.
- Kurzen Systemprompt verwenden.
- Tokenbegrenzung erst dann einschalten, wenn längere Chats Probleme machen.
Genau dafür ist die Oberfläche ausgelegt, denn diese Werte werden pro Chat gespeichert und können je nach Modell oder Aufgabe unterschiedlich gesetzt werden.