Z-OllamaRun – Einstellungen einfach erklärt
Was ist Z-OllamaRun?
Z-OllamaRun ist ein Zusatzprogramm für Z-PromptX. Damit lässt sich der lokale Ollama-Server bequem starten, konfigurieren und überwachen, ganz ohne Batch-Dateien oder Kommandozeile. Die Server-Ausgabe wird dabei direkt im Log-Fenster angezeigt, so dass sich Probleme oder erfolgreiche Starts sofort erkennen lassen.
Ollama selbst ist ein lokaler KI-Server, der Sprachmodelle direkt auf dem eigenen Computer ausführt. Das Programm stellt dafür eine einfache Oberfläche bereit, damit die wichtigsten Einstellungen schnell erreichbar sind.
Erste Schritte
Beim ersten Start
- Pfad zur
ollama.exeprüfen - Unter
OLLAMA_HOSTAdresse und Port eintragen - Auf Ollama Run klicken
Standardmäßig liegt die Datei ollama.exe meist unter C:\Users\IhrName\AppData\Local\Programs\Ollama\ollama.exe. Für den reinen lokalen Betrieb ist 127.0.0.1:11434 die übliche und sichere Voreinstellung.
Ob der Start erfolgreich war, sieht man direkt im Log-Fenster. Sobald dort eine Meldung wie Listening on ... erscheint, läuft der Server und wartet auf Verbindungen.
Hinweis zum Tray
Mit In Tray verschwindet das Fenster in den Infobereich der Taskleiste. Ein Rechtsklick auf das Tray-Symbol öffnet das Menü, ein Doppelklick holt das Fenster wieder zurück.
Wer Autostart & in Tray minimieren aktiviert, kann Ollama beim nächsten Programmstart automatisch starten und das Fenster sofort minimiert im Tray ablegen.
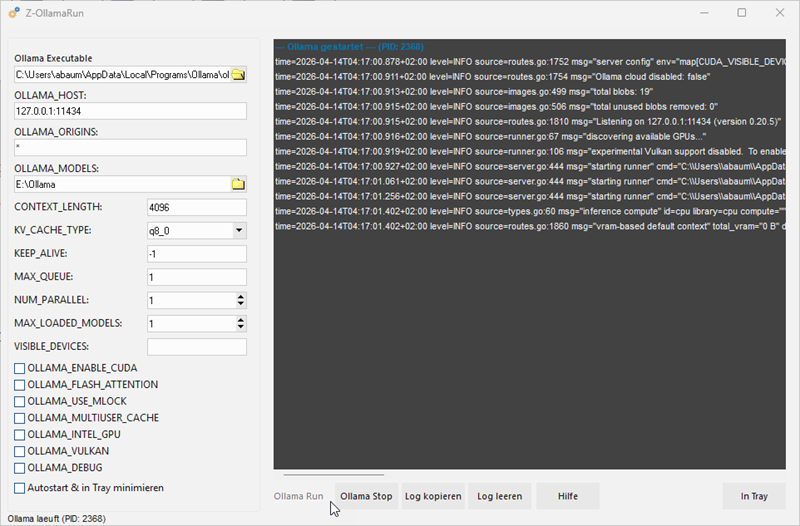
Die wichtigsten Einstellungen
OLLAMA EXECUTABLE PATH
Hier wird der vollständige Pfad zur ollama.exe eingetragen. Über die Schaltfläche mit den drei Punkten lässt sich die Datei direkt auswählen.
Standard: %LOCALAPPDATA%\Programs\Ollama\ollama.exe
OLLAMA_HOST
Dieser Wert bestimmt, auf welcher Adresse und welchem Port Ollama erreichbar ist. Das Format lautet immer IP-Adresse:Port oder Hostname:Port.
Beispiele:
127.0.0.1:11434, nur lokal auf diesem Rechner0.0.0.0:11434, Zugriff aus dem ganzen Netzwerk192.168.2.15:11434, Zugriff nur über eine bestimmte Netzwerkkarte
Empfehlung: Für den normalen Einzelplatzbetrieb 127.0.0.1:11434 verwenden.
OLLAMA_ORIGINS
Hier wird festgelegt, welche Browser-Adressen auf Ollama zugreifen dürfen. Das ist besonders wichtig für browserbasierte Anwendungen wie Z-PromptX.
Beispiele:
*, alle Zugriffe erlaubthttp://localhost, nur lokaler Browser-Zugriff
Empfehlung: Für den einfachen lokalen Betrieb ist * meist die praktischste Einstellung.
OLLAMA_MODELS
Dieser Eintrag bestimmt den Ordner, in dem Ollama die Modelle speichert und sucht. Bleibt das Feld leer, verwendet Ollama den Standardordner im Benutzerprofil.
Wer wenig Platz auf der Systemplatte hat, kann hier einen anderen Speicherort angeben, zum Beispiel auf einer zweiten Festplatte.
Beispiel: E:\Ollama
Praxis-Hinweis: Modelle können mehrere Gigabyte groß sein. Wenn Laufwerk C knapp wird, ist ein eigener Modellordner auf einer anderen Festplatte oft die bessere Lösung.
OLLAMA_CONTEXT_LENGTH
Hier wird die maximale Kontextlänge eingestellt. Gemeint ist die Menge an Text, die das Modell gleichzeitig im Gedächtnis behalten kann.
Größere Werte sind bei längeren Gesprächen oder größeren Dokumenten nützlich, benötigen aber mehr RAM.
Typische Werte:
2048, für einfache Aufgaben und wenig RAM4096, sinnvoller Standardwert8192, für längere Texte32768, nur bei viel RAM sinnvoll
Leer lassen: Dann bestimmt Ollama den Wert automatisch passend zum Modell.
OLLAMA_KV_CACHE_TYPE
Dieser Wert bestimmt das Format des internen K/V-Zwischenspeichers von Ollama. Er beeinflusst vor allem den Speicherverbrauch bei größeren Kontextlängen. Je stärker dieser Zwischenspeicher verkleinert wird, desto eher kann sich das je nach Modell und Aufgabe auf die Qualität der Antworten auswirken.
f16, Standardwert, hohe Genauigkeit, braucht mehr Speicherq8_0, spart deutlich Speicher, meist guter Mittelwegq4_0, spart noch mehr Speicher, kann aber eher Qualität kosten
Empfehlung: Wer genug RAM oder Grafikspeicher hat, lässt diesen Wert auf f16. Wenn Speicher knapp wird, ist q8_0 meist der erste sinnvolle Versuch. q4_0 würde ich nur verwenden, wenn Speicher wirklich knapp ist oder sehr lange Kontexte benötigt werden.
Wichtig: Diese Einstellung ist keine Eigenschaft des Modells selbst. Sie gilt in Ollama global für alle Modelle. Wenn ein bestimmtes Modell mit q8_0 oder q4_0 schlechter läuft, Fehler zeigt oder merkwürdige Antworten liefert, sollte man wieder auf f16 zurückgehen.
Praxis-Hinweis: q8_0 ist ein guter Kompromiss, wenn Speicher gespart werden soll. Der sicherste Standard bleibt aber f16.
OLLAMA_KEEP_ALIVE
Hier wird festgelegt, wie lange ein geladenes Modell nach der letzten Nutzung im Speicher bleibt.
-1, Modell bleibt dauerhaft geladen0, Modell wird nach jeder Anfrage entladen5m, Modell bleibt 5 Minuten geladen30m, Modell bleibt 30 Minuten geladen
Empfehlung: -1 bei regelmäßiger Nutzung, 5m bei gelegentlicher Nutzung.
OLLAMA_MAX_QUEUE
Legt fest, wie viele Anfragen gleichzeitig in der Warteschlange stehen dürfen, wenn Ollama bereits beschäftigt ist.
Empfehlung: Für den Einzelplatzbetrieb genügt meist 1.
OLLAMA_NUM_PARALLEL
Bestimmt, wie viele Anfragen Ollama gleichzeitig bearbeiten kann.
Empfehlung: Für Einzelbenutzer 1, höhere Werte nur bei mehreren gleichzeitigen Nutzern und genügend RAM.
OLLAMA_MAX_LOADED_MODELS
Hier wird festgelegt, wie viele verschiedene Modelle gleichzeitig im Speicher liegen dürfen.
Empfehlung: 1 bei wenig RAM, höhere Werte nur bei genügend Speicher und häufigem Modellwechsel.
CUDA_VISIBLE_DEVICES
Diese Einstellung ist nur für Systeme mit mehreren NVIDIA-Grafikkarten wichtig. Hier kann ausgewählt werden, welche Karte Ollama verwenden soll.
0, erste Grafikkarte1, zweite Grafikkarte0,1, erste und zweite Grafikkarte
Wer nur eine Grafikkarte hat, kann dieses Feld normalerweise leer lassen.
Die Checkboxen kurz erklärt
OLLAMA_ENABLE_CUDA
Aktiviert die Unterstützung für NVIDIA-Grafikkarten. Mit einer passenden GPU laufen Modelle meist deutlich schneller als nur über den Prozessor.
OLLAMA_FLASH_ATTENTION
Eine Optimierung zur Beschleunigung und zur Verringerung des Speicherbedarfs. Wenn unterstützt, ist diese Option oft sinnvoll.
OLLAMA_USE_MLOCK
Verhindert das Auslagern auf die Festplatte. Das kann die Leistung verbessern, setzt aber genügend freien RAM voraus.
OLLAMA_MULTIUSER_CACHE
Gedacht für mehrere gleichzeitige Benutzer. Im normalen Einzelbetrieb meist ohne großen Nutzen.
OLLAMA_INTEL_GPU
Aktiviert die Unterstützung für Intel-Grafik. Sinnvoll, wenn Ollama über eine Intel-GPU beschleunigt werden soll.
OLLAMA_VULKAN
Aktiviert Vulkan als Grafik-Schnittstelle. Das ist vor allem auf AMD-Systemen oder als allgemeiner Grafik-Fallback interessant.
OLLAMA_DEBUG
Schaltet ausführliche technische Meldungen im Log ein. Für die Fehlersuche nützlich, im normalen Betrieb aber meist zu ausführlich.
Die Log-Ausgabe verstehen
Im rechten Bereich zeigt der OllamaLauncher die direkte Server-Ausgabe. Dort lässt sich gut erkennen, ob Ollama korrekt gestartet wurde, welche Einstellungen übernommen wurden und ob CPU oder GPU verwendet wird.
Beispiel für eine typische Log-Zeile
time=2026-03-29T01:03:42.163+01:00 level=INFO source=routes.go:1740 msg="Listening on 127.0.0.1:11434"
Wichtig ist vor allem der Teil level=.
- INFO, normale Betriebsmeldung
- DEBUG, technische Details für die Fehlersuche
- WARN, Hinweis auf mögliche Probleme
- ERROR, echter Fehler, der beachtet werden sollte
Wichtige Meldungen im Log
server config
Zeigt alle aktiven Einstellungen beim Start. Hier lässt sich gut prüfen, ob die Werte korrekt übernommen wurden.
total blobs: X
Zeigt, wie viele Modelldateien gefunden wurden. Steht hier 0, wurden keine Modelle im eingetragenen Ordner gefunden.
Listening on …
Die wichtigste Meldung beim Start. Sie zeigt, dass der Server läuft und auf Anfragen wartet.
discovering available GPUs…
Ollama sucht nach nutzbarer Grafikbeschleunigung.
inference compute id=cpu library=cpu
Ollama arbeitet nur über den Prozessor.
inference compute id=gpu library=cuda
Ollama nutzt eine NVIDIA-Grafikkarte.
starting runner cmd=…
Ollama startet interne Hilfsprozesse. Diese Meldung ist normal.
[GIN] … GET „/api/tags“
Das sind normale HTTP-Anfragen an den internen Webserver von Ollama.
Statuscodes: 200 erfolgreich, 404 nicht gefunden, 500 interner Fehler
Typischer Startablauf
server config, Einstellungen werden angezeigttotal blobs: X, Modelle werden gezähltListening on ..., Server ist erreichbardiscovering available GPUs, Hardware wird geprüftstarting runner, interne Prozesse werden gestartetinference compute, CPU oder GPU wird festgelegt[GIN], erste Anfragen von Z-PromptX oder anderen Programmen
Spätestens nach dem Schritt inference compute ist Ollama normalerweise vollständig betriebsbereit.
Häufige Probleme
listen tcp: bind: address already in use
Der Port ist bereits belegt. Entweder läuft schon eine andere Ollama-Instanz oder ein anderes Programm benutzt denselben Port.
no such file or directory
Der angegebene Modellordner existiert nicht. Pfad prüfen oder den Ordner anlegen.
permission denied
Ollama hat keine ausreichenden Rechte auf einen Ordner. In diesem Fall die Berechtigungen prüfen.
total blobs: 0
Es wurden keine Modelle gefunden. Meist stimmt der Modellpfad nicht oder es wurden noch keine Modelle heruntergeladen.
Häufige Fragen
Ollama startet, aber Z-PromptX kann keine Verbindung herstellen
Prüfen, ob OLLAMA_ORIGINS auf * steht und ob die in Z-PromptX eingetragene Adresse wirklich mit OLLAMA_HOST übereinstimmt.
Die Antworten sind sehr langsam
Dann läuft Ollama wahrscheinlich nur über die CPU. In diesem Fall prüfen, ob GPU-Beschleunigung aktiv ist und im Log Meldungen wie library=cuda oder library=vulkan erscheinen.
Ollama beendet sich direkt nach dem Start
Hier hilft ein Blick in das Log-Fenster. Häufige Ursachen sind ein belegter Port oder ungültige Einstellungen.
Das Log ist viel zu ausführlich
Dann ist wahrscheinlich OLLAMA_DEBUG aktiviert. Die Checkbox deaktivieren und den Server neu starten.
Wo werden die Einstellungen gespeichert
In der Datei OllamaLauncher.ini im selben Ordner wie das Programm. Diese Datei kann auch mit einem Texteditor geöffnet werden.
Kann Ollama auch ohne den Launcher gestartet werden
Ja. Ollama lässt sich auch direkt per ollama serve starten. Der Launcher ist aber deutlich bequemer, weil sich damit alle wichtigen Umgebungsvariablen ohne Batch-Dateien verwalten lassen.