 Brauche ich für vorhandene Antwortvorlagen schon ein RAG System?
Brauche ich für vorhandene Antwortvorlagen schon ein RAG System?
Wer sich mit KI bei der Bearbeitung von E-Mails beschäftigt, stößt früher oder später auf den Begriff RAG. Gemeint ist damit vereinfacht gesagt eine KI mit Nachschlagefunktion. Bevor die Antwort geschrieben wird, sucht das System in vorhandenen Wissensquellen nach passenden Inhalten, zum Beispiel in Dokumenten, Handbüchern, alten E-Mails oder Datenbanken. Erst danach formuliert die KI daraus eine Antwort.
Das klingt erst einmal sinnvoll. Die eigentliche Praxisfrage ist aber eine andere. Brauche ich diesen Aufwand überhaupt schon, wenn ich bereits mit vorhandenen Antwortvorlagen arbeite?
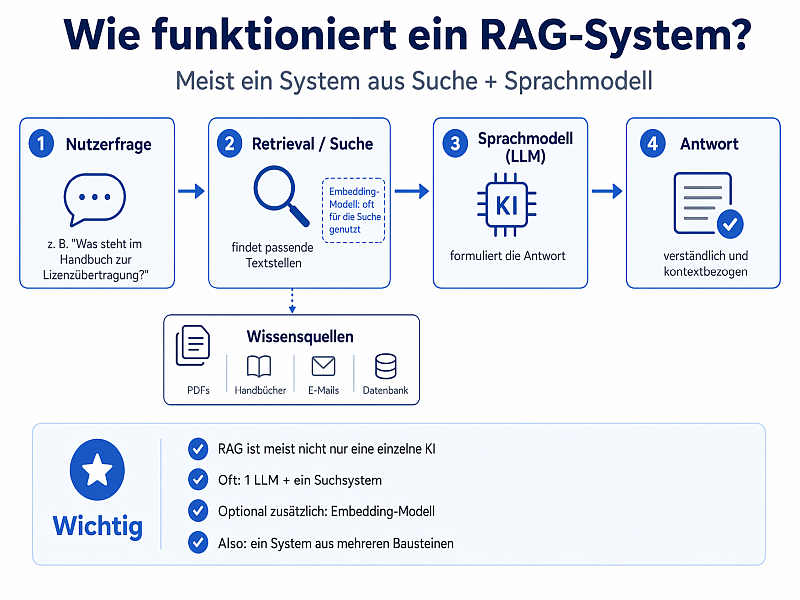
Mein Eindruck aus der Praxis ist bisher ziemlich klar. Meistens nein. Gerade bei E-Mail Antworten wird schnell so getan, als wäre RAG automatisch der nächste logische Schritt. Vorlagen da, KI da, also bitte noch Suche, Embeddings, Vektordatenbank und das ganze Programm dazu. In der Theorie klingt das modern. In der Praxis baut man sich damit aber schnell mehr Technik als Nutzen.
Bei mir ist die Ausgangslage recht simpel. Es gibt bereits vorhandene Antwortvorlagen. Also nicht die Situation, dass eine KI völlig frei aus einem riesigen Wissenshaufen irgendetwas zusammenraten soll. Die eigentliche Frage ist deshalb nicht, ob Wissen vorhanden ist. Die Frage ist, wie man dieses Wissen sauber und brauchbar in die Antworterstellung hineinbekommt.
Warum ich Prompt und Antwortvorlagen trenne
Ich trenne das bewusst. Es gibt einen Prompt und es gibt Antwortvorlagen. Das ist für mich kein akademischer Unterschied, sondern reine Praxis. Im Prompt steht, wie die KI arbeiten soll. Also Stil, Regeln, Grenzen und feste Vorgaben. In den Antwortvorlagen steckt der eigentliche Inhalt für den jeweiligen Fall. Genau diese Trennung ist wichtig, weil sonst alles in einem großen Brei endet. Regeln, Schreibstil und Inhalte stehen dann bunt gemischt in einem einzigen Block. Das kann funktionieren, ist aber auf Dauer einfach unsauber.
Getrennt ist das Ganze deutlich angenehmer zu pflegen. Wenn ich eine Formulierung in einer Vorlage ändere, muss ich nicht am Prompt herumschrauben. Und wenn ich die Regeln für die KI ändere, bleiben die Vorlagen in Ruhe. Das ist übersichtlicher, wartungsfreundlicher und im Alltag einfach weniger nervig.
Theoretisch könnte man das ganze Wissen natürlich auch direkt mit in verschiedene Prompts kippen. Bei einer einzelnen E Mail Antwort ist die reine Größe des Prompts oft gar nicht das Hauptproblem. Das ist ja kein endloser Chatverlauf, der immer weiter anwächst. Trotzdem halte ich die Trennung für die sauberere Lösung. Nicht weil das Modell sonst gleich umfällt, sondern weil die Struktur klar bleibt.
Nicht jedes Dokument taugt als Vorlage für ein LLM
Was mir bei meinen Tests mit rund 800 Seiten vorhandener Dokumentation noch einmal deutlich aufgefallen ist, war etwas anderes. Nicht jedes Dokument taugt automatisch als Vorlage für ein LLM. Das wird in vielen Erklärungen gern zu glatt dargestellt. Ein Text kann für einen Menschen völlig verständlich sein und für das Modell trotzdem eine miserable Arbeitsgrundlage abgeben. Dann zieht das LLM falsche Schlüsse, hängt sich an Nebensachen auf oder formuliert am Ende an der eigentlichen Sache vorbei. Einen praktischen Nutzen hatte der Aufwand allerdings: Ich weiß jetzt, wie sich ein RAG-System auch lokal aufbauen lässt.
Genau da liegt für mich ein ganz praktischer Haken. Es reicht eben nicht, einfach vorhandene Texte an eine KI dranzuhängen und zu hoffen, dass schon etwas Brauchbares herauskommt. Manche Dokumente sind für Menschen geschrieben, nicht für Sprachmodelle. Das ist ein Unterschied. Ein Mensch liest auch zwischen den Zeilen. Ein LLM baut aus dem Material Muster. Und wenn das Material unsauber, gemischt oder missverständlich ist, kommt eben auch Unsinn dabei heraus.
Deshalb ist für mich nicht nur die Menge an Wissen wichtig, sondern auch die Form. Eine brauchbare Vorlage für ein LLM muss klar, eindeutig und zielgerichtet sein. Sonst baut man sich technisch immer mehr zusammen und wundert sich am Ende, warum die Antworten trotzdem nicht sauber werden.
Wann ein einfacherer Aufbau oft völlig reicht
Genau aus dem Grund sehe ich vorhandene Antwortvorlagen noch lange nicht als automatische Einladung, jetzt ein RAG System aufzubauen. Wenn die Vorlagen thematisch halbwegs sauber getrennt sind, sinnvoll ausgewählt werden können und für die KI überhaupt taugen, dann kommt man mit einem deutlich einfacheren Aufbau oft schon sehr weit.
Nicht die reine Anzahl entscheidet darüber, ob ein RAG System nötig ist. Wichtiger ist, ob sich die passenden Inhalte noch gezielt auswählen lassen und ob die vorhandenen Dokumente überhaupt so aufgebaut sind, dass ein LLM sauber damit arbeiten kann.
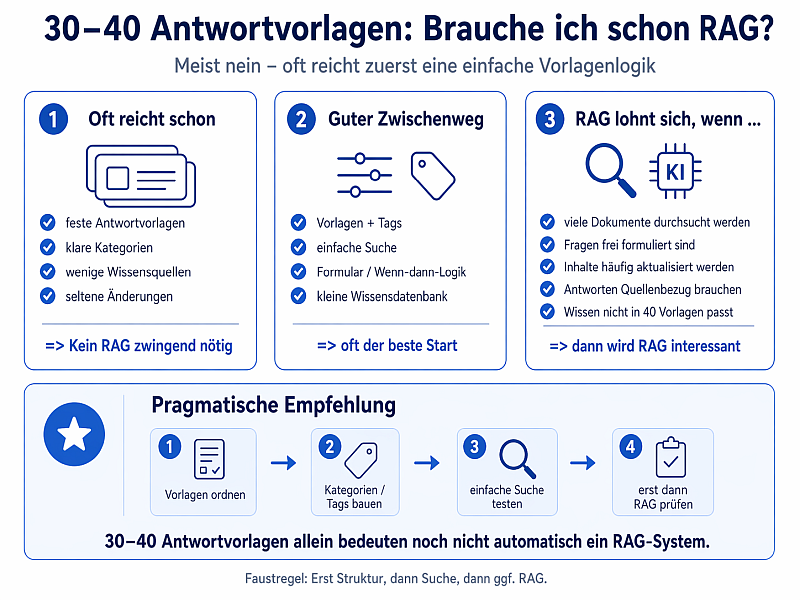
RAG wird aus meiner Sicht vor allem dann interessant, wenn die Zahl der Quellen deutlich wächst, etwa über 100 hinaus, oder wenn sich die passende Information nicht mehr sinnvoll über feste Vorlagen und einfache Auswahlmechanismen finden lässt. Vorher bedeutet ein RAG-System oft vor allem mehr Zeitaufwand, mehr Pflege und damit auch mehr Kosten.
Mein Fazit
Mein Fazit ist deshalb recht nüchtern. Nur weil bereits Antwortvorlagen vorhanden sind, braucht man noch kein RAG System. Oft ist es sinnvoller, zuerst die bestehenden Vorlagen ordentlich zu strukturieren, Prompt und Inhalte sauber zu trennen und kritisch zu prüfen, welche Texte für ein LLM überhaupt als Vorlage taugen. Das wirkt weniger spektakulär als ein RAG System, ist im Alltag aber oft die vernünftigere Lösung.
Wenn der Bestand später wächst, die Fälle freier werden und die Suche nach passenden Inhalten schwieriger wird, kann man über RAG immer noch nachdenken. Aber nur weil das technisch gerade modern klingt, muss man es nicht automatisch sofort einbauen.