
Wenn ich ein neues lokales Modell teste, lasse ich es nicht sofort auf meine echten Aufgaben los. Ich will zuerst wissen, womit ich es überhaupt zu tun habe. Wie alt ist das Wissen, wo liegen die Stärken, und bei welchen Fragen sollte man besser nicht zu viel erwarten. Genau dafür nutze ich ein paar einfache Einstiegs Prompts.
Das klingt erst mal unspektakulär, spart mir später aber oft Zeit und Nerven. Gerade bei lokalen Modellen sagt der Name allein noch nicht viel aus. Manche wirken auf den ersten Blick beeindruckend, liefern im Alltag dann aber nur Mittelmaß. Andere klingen kleiner und unscheinbarer, sind dafür aber erstaunlich brauchbar, wenn man sie passend einsetzt.
Warum ich ein neues Modell nicht sofort produktiv nutze
Ein neues Modell kann sich in den ersten Antworten ziemlich gut verkaufen. Das heißt aber noch lange nicht, dass es später auch sauber arbeitet. Genau deshalb mache ich am Anfang keine großen Kunststücke, sondern ein paar kurze Tests. Ich will erst eine grobe Einschätzung, bevor ich damit arbeite.
Dabei geht es mir nicht um irgendwelche Laborwerte oder um die perfekte Benchmark. Ich will sehen, ob das Modell klar antwortet, ob es seine Grenzen halbwegs realistisch beschreibt und ob es schon bei einfachen Fragen sauber in der Spur bleibt. Mehr braucht es für den Anfang oft gar nicht.
Der erste Prompt, Wissensstand, Stärken und Grenzen
Mein erster Prompt ist ganz einfach. Ich frage das Modell nach seinem Wissensstand, nach seinen starken Themenbereichen und nach den Punkten, bei denen es vorsichtig sein sollte. Das ist kein tiefer Techniktest, aber ein guter erster Filter. Schon an dieser Antwort merkt man oft, ob ein Modell eher klar und brauchbar ist oder ob es nur geschniegelt formuliert.
Bis wann reicht dein Wissensstand? In welchen Themenbereichen bist du besonders stark? Bei welchen Arten von Fragen bist du eingeschränkt oder solltest vorsichtig antworten? Antworte strukturiert in drei Abschnitten und halte jeden Abschnitt bei 2-4 Sätzen.
Wissensstand: Meine Trainingsdaten reichen bis Ende 2024, was bedeutet, dass ich aktuelle Ereignisse bis zu diesem Zeitpunkt berücksichtigen kann. Für Informationen jenseits dieses Zeitraums sollte ich vorsichtig sein und auf externe Quellen verweisen. Stärken: Ich bin in Bereichen mit reichhaltigen Daten und klaren Mustern stark, wie z. B. Naturwissenschaften, Technologie oder allgemeine Fakten. Meine Fähigkeiten sind jedoch auf die Verarbeitung und Synthese dieser Daten beschränkt. Einschränkungen: Bei subjektiven Themen (z. B. Meinungen, kulturelle Interpretationen) oder ambigen Fragen (z. B. ethische Dilemmata) sollte ich vorsichtig sein und klare Grenzen setzen. Schnell verändernde Informationen oder spezialisierte Fachgebiete erfordern oft zusätzliche Quellen.
Die Antwort von qwen3:8b auf diesen ersten Test fand ich durchaus ordentlich. Der Wissensstand wurde klar benannt, die Stärken klangen nicht völlig aus der Luft gegriffen, und bei den Einschränkungen war zumindest ein gewisses Problembewusstsein zu erkennen. Das ist noch kein Beweis für ein starkes Arbeitsmodell, aber ein brauchbarer Anfang.
Wichtig ist dabei auch, wie ein Modell mit seinen Schwächen umgeht. Wenn es so tut, als könne es praktisch alles, werde ich sofort misstrauisch. Gute Antworten müssen hier nicht besonders lang sein. Es reicht schon, wenn klar wird, dass aktuelle Themen, heikle Bewertungen oder rechtliche und sicherheitskritische Fragen nicht einfach nebenbei mit erledigt werden sollten.
Die längere Variante für einen zweiten Blick
Wenn der erste Eindruck brauchbar ist, gehe ich oft noch einen Schritt weiter. Dann darf das Modell ausführlicher antworten. Damit prüfe ich weniger den Inhalt als die Stabilität. Kleine Modelle können in kurzen Absätzen durchaus ordentlich wirken und in längeren Antworten trotzdem anfangen zu schwimmen.
Analysiere deinen Wissensstand sowie deine Kernkompetenzen umfassend. Nenne das Datum deines letzten Trainingsdatensatzes und erläutere die Relevanz für aktuelle Ereignisse. Beschreibe detailliert deine Stärken in technischen, kreativen und analytischen Fachbereichen. Identifiziere spezifische Grenzen bei ethischen, rechtlichen oder sicherheitskritischen Anfragen. Strukturiere die Antwort in drei detaillierte Abschnitte mit jeweils mindestens sechs Sätzen.
Wissensstand und Relevanz für aktuelle Ereignisse: Meine Trainingsdaten stammen aus dem Oktober 2024, was bedeutet, dass ich Ereignisse und Entwicklungen bis zu diesem Zeitpunkt umfassend berücksichtigen kann. Für Informationen jenseits dieses Datums sollte ich vorsichtig sein und auf aktuelle Quellen verweisen. Die Relevanz meiner Daten für aktuelle Ereignisse hängt davon ab, ob diese in den Trainingsdaten enthalten waren. Bei schnellen Veränderungen, wie z. B. politische Entscheidungen oder technologische Fortschritte, kann meine Kenntnis lückenhaft sein. Ich kann jedoch Hilfen anbieten, um aktuelle Informationen zu finden. Für zeitkritische Themen empfehle ich ergänzende Recherchen. Kernkompetenzen in technischen, kreativen und analytischen Bereichen: In technischen Themen bin ich stark in Bereichen wie Programmierung, KI-Modellierung und Ingenieurswissenschaften. Ich kann Code-Beispiele erstellen, Algorithmen erklären und technische Dokumentationen verfassen. Kreativität spiele ich in der Schreibkunst, in der Erstellung von Geschichten oder in der Generierung von Kunstwerken. Hier kombiniere ich Struktur mit Fantasie. Analytisch bin ich in der Lage, Daten zu interpretieren, Problemlösungen zu strukturieren und komplexe Zusammenhänge zu verdeutlichen. Meine Fähigkeiten umfassen auch die Durchführung von logischen Beweisen und die Bewertung von Hypothesen. In allen Bereichen setze ich auf klare, nachvollziehbare Erklärungen. Grenzen bei ethischen, rechtlichen oder sicherheitskritischen Anfragen: Bei ethischen Fragen, wie z. B. KI-Ethik oder Datenschutz, achte ich auf Neutralität und verweise auf etablierte Richtlinien. Ich kann jedoch nicht die moralische Bewertung von Entscheidungen ersetzen. Rechtliche Anfragen, insbesondere zu nationalen oder internationalen Gesetzen, werden mit Vorsicht behandelt, da meine Daten nicht immer aktuelle Änderungen enthalten. Sicherheitskritische Themen, wie z. B. Cyberangriffe oder Hacker-Methoden, werden nicht detailliert beschrieben, um Risiken zu minimieren. Ich kann jedoch allgemeine Informationen zur Sicherheitspraxis bereitstellen. Spezialisierte Fachfragen in diesen Bereichen erfordern oft Expertise oder externe Quellen. Meine Antworten sind stets darauf ausgerichtet, Schaden zu vermeiden und Neutralität zu wahren.
Auch hier hat sich qwen3:8b ordentlich geschlagen. Die Struktur blieb sauber, die Antwort war nachvollziehbar, und gerade bei technischen und analytischen Themen klang die Selbsteinschätzung plausibel. Im kreativen Bereich wurde es etwas allgemeiner, aber das ist bei solchen Antworten nicht ungewöhnlich. Für mich war das jedenfalls genug, um dem Modell noch einen zweiten praktischen Test zu geben.
Vom ersten Eindruck zum eigentlichen Alltagstest
Nach diesem ersten Block weiß ich grob, wie das Modell sich selbst einordnet. Das ist ganz nützlich, reicht mir aber noch nicht. Denn ein Modell kann sich sauber beschreiben und bei echten Aufgaben trotzdem Unsinn machen. Genau deshalb kommt bei mir danach fast immer noch ein zweiter Prompt, der stärker auf den späteren Alltag zielt.
Ab da interessiert mich nicht mehr nur, was das Modell über seinen Wissensstand erzählt. Ich will wissen, wie es überhaupt sinnvoll angesprochen werden möchte. Also ganz praktisch. Welche Prompt Struktur hilft. Wie wichtig sind Kontext, Ziel, Rolle und Ausgabeform. Und ob das Modell in der Lage ist, daraus brauchbare Hinweise zu machen.
Der zweite Prompt, wie ein Modell eigentlich angesprochen werden will
Mein zweiter Prompt ging erst einmal bewusst in diese Richtung. Ich wollte wissen, wie das Modell seine eigene Arbeitsweise beschreibt und welche Art von Anweisungen aus seiner Sicht zu besseren Ergebnissen führt. Gerade dieser Schritt ist spannend, weil viele Modelle dabei erstaunlich selbstsicher klingen. Genau da sollte man aber nicht alles ungeprüft glauben.
Analysiere deine interne Architektur und Logik um eine Anleitung fuer optimales Prompting zu erstellen. Beschreibe welche Struktur und welche Schluesselwoerter bei dir die praezisesten Ergebnisse erzielen. Erklaere wie Kontext und Rollenzuweisungen deine Antwortqualitaet beeinflussen. Gib konkrete Beispiele fuer effektive Anweisungen und nenne Formulierungen die zu Missverstaendnissen fuehren koennen. Strukturiere die Antwort in logische Schritte von der Aufgabenstellung bis zur Formatvorgabe.
Interne Architektur und Logik für optimales Prompting: Meine interne Architektur basiert auf einer neuronalen Netzwerkstruktur, die aus Encoder- und Decoder-Schichten besteht. Der Encoder analysiert den Eingangstext, um semantische Muster zu erkennen, während der Decoder basierend auf dem Kontext und den Trainingsdaten eine Antwort generiert. Die Aufmerksamkeitsmechanismen (Attention) ermöglichen es mir, relevante Teile des Kontexts zu fokussieren. Um präzise Ergebnisse zu erzielen, ist eine klare Struktur der Anfrage entscheidend. Die Logik folgt einem sequenziellen Prozess: Verständnis der Aufgabe, Kontextanalyse, Generierung der Antwort unter Berücksichtigung von Einschränkungen. Struktur und Schlüsselwörter für präzise Ergebnisse: Eine effektive Anfrage besteht aus vier Elementen: 1) Aufgabenbeschreibung (z. B. "Erkläre den Klimawandel"), 2) Kontext (z. B. "basierend auf wissenschaftlichen Studien"), 3) Einschränkungen (z. B. "in 300 Wörtern"), 4) Formatvorgabe (z. B. "als Liste"). Schlüsselwörter wie "analysieren", "vergleichen", "beispielhaft" oder "kritisieren" lenken die Antwort in spezifische Richtungen. Präzision entsteht durch klare, unmissverständliche Formulierungen. Vage Begriffe wie "erkläre" ohne weitere Details führen oft zu ungenügend präzisen Antworten. Kontext und Rollenzuweisungen für Antwortqualität: Kontext ist entscheidend, da er die Grundlage für eine relevante Antwort bildet. Ohne Kontext können generierte Texte ungenau oder irrelevant sein. Rollenzuweisungen (z. B. "Als Experte für Klimawissenschaften") prägen die Antwortstil und Tiefe. Ein klarer Kontext reduziert Missverständnisse, während eine präzise Rolle die Antwort auf Fachniveau ausrichtet. Beispielsweise führt die Rolle eines "Lehrers" zu detaillierten Erklärungen, während ein "Forscher"-Modus fokussiert auf Daten und Quellen. Fehlende Rollenklärung kann zu allgemeinen, weniger nützlichen Antworten führen. Beispiele für effektive und missverständnisfördernde Formulierungen: Effektiv: "Erkläre die Funktion von DNS in 300 Wörtern, basierend auf technischen Quellen." Missverständnisfördernd: "Schreibe über DNS", zu vage. Effektiv: "Vergleiche die Vor- und Nachteile von KI-Modellen in einer Tabelle." Missverständnisfördernd: "Erkläre KI", zu allgemein. Effektiv: "Analysiere die ethischen Risiken von KI in einem strukturierten Bericht." Missverständnisfördernd: "Diskutiere KI-Ethik", fehlt Kontext. Präzision entsteht durch explizite Anweisungen und klare Struktur.
Die Antwort war auf den ersten Blick durchaus brauchbar. Vor allem der Teil mit Aufgabenbeschreibung, Kontext, Einschränkungen und Formatvorgabe ist im Alltag sofort verständlich. Genau solche Hinweise sind für die Praxis nützlich. Keine große Show, sondern etwas, womit man direkt arbeiten kann.
Etwas vorsichtiger bin ich aber bei dem Teil zur angeblichen internen Architektur. Sobald ein Modell mit Encoder, Decoder oder ähnlichen Begriffen anfängt, wird es schnell allgemein. Das muss nicht komplett falsch sein, sagt aber oft mehr über übliche KI Erklärungen aus als über das konkrete Modell selbst. Für mich ist der brauchbare Teil deshalb nicht die Technikbeschreibung, sondern der praktische Nutzen für besseres Prompting.
Und genau das ist am Ende auch der eigentliche Punkt. Ich will von einem neuen Modell nicht hören, wie klug es sich selbst beschreibt. Ich will sehen, ob es mir brauchbar sagen kann, wie ich gute Anweisungen formuliere. Wenn es das schon nicht sauber hinbekommt, wird der Rest meistens auch nicht besser.
Ein leerer Chat macht oft mehr aus, als man denkt
Was ebenfalls gern unterschätzt wird, ist der bisherige Verlauf im Chat. Ein Modell reagiert nicht nur auf den letzten Satz, sondern auch auf das, was aus dem Gespräch noch im wirksamen Kontext steckt. In einem frischen Chat kann derselbe Prompt sauber funktionieren. In einem langen Verlauf mit altem Ballast wird die Antwort plötzlich unklar, unsauber oder widersprüchlich.
Genau deshalb teste ich neue Modelle möglichst in einem leeren Chat. Für meine tägliche Arbeit nutze ich zwar feste Chats pro Aufgabe mit gleichbleibenden Einstellungen, aber wenn das Thema erledigt ist, lösche ich den Inhalt wieder. So starte ich beim nächsten Thema sauber neu. Gerade kleinere lokale Modelle danken einem das oft mehr, als man zuerst denkt.
Danach kommen erst die echten Mini Aufgaben
Nach diesen beiden Einstiegs Prompts mache ich keine Grundsatzdiskussionen mehr mit dem Modell. Dann muss es zeigen, was es praktisch kann. Ich nehme dafür kleine Aufgaben aus meinem Alltag. Einen kurzen Erklärungstext, eine Umformulierung, vielleicht eine einfache technische Frage. Mehr braucht es für einen ersten Praxischeck nicht.
Genau da trennt sich dann oft ziemlich schnell die Selbstdarstellung von der tatsächlichen Qualität. Ein Modell kann sich vorher sehr ordentlich beschreiben und bei der ersten echten Aufgabe trotzdem danebenliegen. Deshalb sind die ersten Prompts für mich nur der Anfang. Die eigentliche Prüfung kommt direkt danach.
Was bedeutet der Parameter "serve" bei Ollama.exe
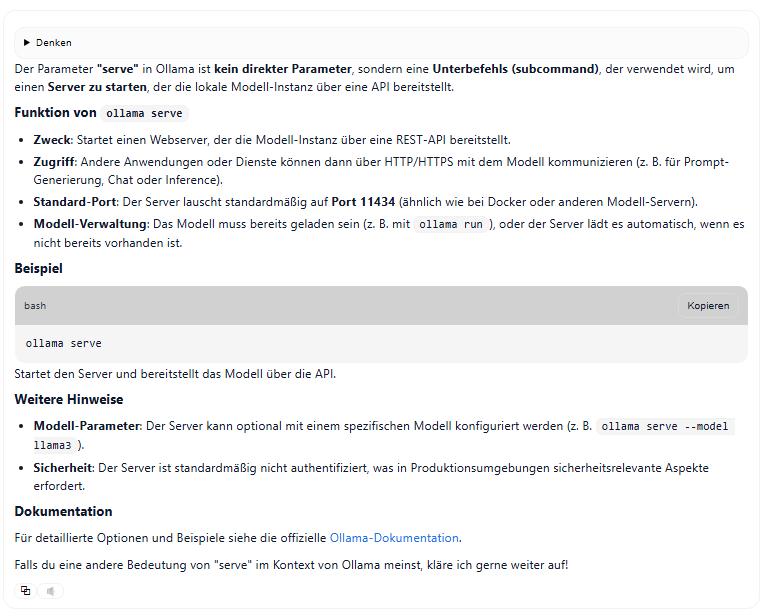

Mein Fazit
Die ersten Prompts bei einem neuen Modell müssen nicht besonders raffiniert sein. Sie sollen nur schnell zeigen, womit man es zu tun hat. Wissensstand, Stärken, Grenzen, und danach die Frage, wie das Modell sinnvoll angesprochen werden will. Das reicht für den Anfang völlig aus.
Danach zählt sowieso nicht mehr, was das Modell über sich selbst erzählt. Entscheidend ist, was bei echten Aufgaben herauskommt. Genau deshalb fange ich mit ein paar einfachen Prüffragen an und nicht gleich mit produktiver Arbeit. Das ist unspektakulär, aber im Alltag meistens der bessere Weg.