
Wenn man anfängt, mit einer lokalen KI zu arbeiten, schaut man zuerst fast automatisch auf den Prompt. Ist ja auch naheliegend. Das ist schließlich der Teil, den man selbst direkt eingibt. Also denkt man erst mal, dass gute Antworten vor allem davon abhängen, ob der Prompt gut geschrieben ist.
Ganz falsch ist das nicht. Ein schlechter oder unklarer Prompt macht die Sache selten besser.
Aber nach meinen ersten Versuchen mit lokaler KI hatte ich ziemlich schnell den Eindruck, dass das nur die halbe Wahrheit ist. Dieselbe Eingabe kann erstaunlich unterschiedlich ausfallen, obwohl man am Prompt kaum etwas geändert hat.
Der Grund ist simpel. Nicht nur der Prompt spielt mit rein, sondern auch das Modell, der bisherige Chatverlauf und die Einstellungen im Chatfenster. Und genau das geht in vielen Erklärungen im Internet etwas unter. Dort klingt es oft so, als müsse man nur den einen perfekten Prompt finden, dann läuft der Rest schon. In der Praxis ist das aber deutlich weniger romantisch.
Ich habe das recht schnell gemerkt. Einmal antwortet die KI ruhig und brauchbar. Beim nächsten Versuch wird sie plötzlich länger, freier oder auch unsauberer, obwohl der Prompt fast gleich geblieben ist. Dann liegt das Problem eben nicht immer am Prompt. Oft sitzt es eine Ebene tiefer, also bei den Einstellungen.
Temperatur, Top P und Seed
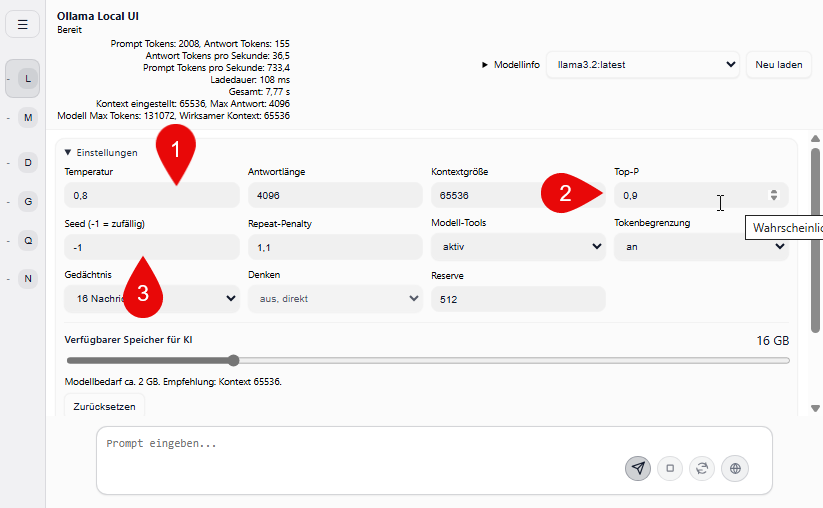
Ein gutes Beispiel dafür ist die Temperatur. Damit steuert man vereinfacht gesagt, wie frei oder wie streng die KI antwortet. Bei niedrigen Werten bleibt sie oft nüchterner, berechenbarer und etwas geordneter. Dreht man höher, wird die Ausgabe lockerer, kreativer und manchmal auch ein Stück ungenauer. Für technische Fragen, sachliche Texte oder klare Zusammenfassungen passt meist eher ein ruhigerer Wert. Für Ideen, Umformulierungen oder etwas freiere Texte darf es ruhig mehr sein.
Ähnlich ist es mit Top P. Das ist so ein Regler, den viele anfangs kaum beachten. Er beeinflusst aber ebenfalls, wie breit die KI bei möglichen Formulierungen auswählt. Im Alltag merkt man das nicht immer sofort, aber es wirkt mit. Schwierig wird es dann, wenn man Temperatur und Top P gleichzeitig ständig verändert. Dann weiß man irgendwann nicht mehr, ob die bessere Antwort nun am neuen Prompt lag oder einfach nur an anderen Werten.
Der Seed ist noch mal ein anderes Thema. Den übersieht man leicht, obwohl er beim Vergleichen ziemlich nützlich sein kann. Wenn der Seed fest gesetzt ist, lassen sich Antworten unter gleichen Bedingungen besser nachvollziehen. Gerade beim Testen merkt man dann eher, ob ein neuer Prompt wirklich besser war oder ob die KI einfach nur anders gewürfelt hat.
Repeat Penalty und Antwortlänge
Dann gibt es noch die Wiederholungsbremse, meist als Repeat Penalty bezeichnet. Die macht oft mehr aus, als man zuerst denkt. Ist der Wert zu niedrig, dreht sich die KI gern mal im Kreis oder wiederholt Formulierungen. Ist er zu hoch, klingt der Text schnell etwas steif. Auch hier gibt es also keinen Wunderwert, der immer passt. Man muss schauen, was man überhaupt will.
Ein zu niedriger Wert bringt kaum Wirkung. Ein zu hoher Wert kann Texte unnatürlich machen, weil das Modell normale Wiederholungen zu stark vermeidet. Fuer viele praktische Aufgaben, etwa Support oder E-Mail-Antworten, ist ein Wert um 1.1 oft ein brauchbarer Startpunkt.
| Wert | Wirkung |
|---|---|
| 1.0 | Kaum zusaetzliche Bremse gegen Wiederholungen. |
| 1.05 bis 1.15 | Oft ein guter Praxisbereich fuer ruhigere und weniger doppelte Formulierungen. |
| Deutlich hoeher | Kann den Text verkrampft oder unnatuerlich wirken lassen. |
Ähnlich ist es bei der Antwortlänge. Wenn der Wert zu knapp gesetzt ist, bleibt die Antwort oberflächlich oder hört zu früh auf. Dann verdächtigt man schnell den Prompt, obwohl die KI schlicht zu wenig Platz hatte. Stellt man die Länge dagegen sehr hoch ein, wird es auch nicht automatisch besser. Manche Modelle reden dann einfach mehr, ohne dass wirklich mehr Inhalt herauskommt.
Der Chat selbst spielt ebenfalls mit
Was ebenfalls gern unterschätzt wird, ist der bisherige Verlauf im Chat. Eine KI reagiert nicht nur auf den letzten Satz, sondern auf das, was vom Gespräch noch im wirksamen Kontext steckt. Ich habe mir deshalb angewöhnt, für meine täglichen Arbeiten je Aufgabe einen eigenen Chat zu benutzen. Die Einstellungen bleiben gleich, den Inhalt des Chats lösche ich aber nach Abschluss der Aufgabe wieder. So schleppe ich beim nächsten Thema keinen alten Ballast mit.
| Einsatz/Chat | Profil | Temperatur | top_p | repeat_penalty | Wirkung |
|---|---|---|---|---|---|
| Support, Reklamationen, technische Antworten, nüchterne Kundenmails | Sehr sachlich und stabil | 0,2 | 0,85 | 1,1 | Ruhig, berechenbar, wenig Ausschmückung |
| Normale Geschäftsmails, freundlich aber noch sachlich | Etwas natürlicher | 0,35 | 0,9 | 1,1 | Etwas lockerer, ohne ins Schwafeln zu kippen |
| Textvarianten, freundlichere Formulierungen, Entwürfe mit mehr Sprachfluss | Freier formuliert | 0,55 | 0,95 | 1,05 | Mehr Variation, aber weniger kontrolliert |
Das ist für mich im Alltag oft wichtiger als noch eine kleine Änderung am Prompt. In einem frischen Chat funktioniert dieselbe Eingabe häufig sauberer als in einem langen Verlauf mit älteren Themen. Wenn Antworten unklar werden oder frühere Vorgaben verloren gehen, ist also nicht automatisch der Prompt schlecht. Manchmal ist der Chat einfach zu voll, oder das Modell passt nicht richtig zur Aufgabe.
Der Prompt bleibt wichtig, aber eben nicht allein
Genau da fängt für mich das eigentliche Prompten mit lokaler KI an. Es geht nicht nur darum, einen Satz möglichst schlau zu formulieren. Es geht auch darum, das Modell und die Einstellungen so hinzubekommen, dass die Antwort überhaupt in die gewünschte Richtung laufen kann.
Der Prompt ist also wichtig, klar. Aber er ist nicht der einzige Hebel. Bei lokaler KI zählt immer das Zusammenspiel aus Prompt, Modell, Verlauf und Einstellungen. Wenn das halbwegs zusammenpasst, wird aus einer guten Eingabe meist auch eine brauchbare Antwort. Wenn nicht, kann man am Prompt schrauben, bis man schwarz wird.